CP 6691 - Week 1
Format of a Journal Article
Evaluating Research Reports
Interactive Table of Contents (Click on any Block)
 Format of a Journal Article Format of a Journal Article
The Introductory Section
Research Hypotheses, Questions, and Objectives
Research Procedures
Random Sampling Methods
Nonrandom Sampling Methods
Estimating Sample Size
Volunteer Samples and Nonrespondent Bias
Assignment for Week 2
Format of a Journal Article
- Abstract
- Introduction
- Statement of specific hypotheses, questions, or objectives that guide the study
- Description of research procedures (sometimes called methodology)
- Report of findings
- Discussion
Most quantitative journal articles follow this format. Each of these sections contains information that can be evaluated to help
you determine the extent to which you have confidence in the results of the study. Each section needs to be evaluated separately because each is subject to different flaws.
The Introductory Section
May contain information about the researchers (their affiliations, why they did the study, are they committed to a particular point
of view, etc.) This information is important in evaluating because it may suggest a motive for bias in the research.
A Word About Bias
In the language of social science research, some terms take on different meanings than they do in everyday usage. Bias, for example, is such a term. In research, bias simply means error. So, when I said above that information about the researcher might suggest a motive for bias in the research, I was talking only about the possibility of error creeping into the procedures.
For example, say a study is reported which shows no causal link between second-hand cigarette smoke and respiratory disease. On its face, this finding is interesting since it is contrary to a number of other studies that show a strong possible link between second-hand smoke and respiratory disease. As we read through the introduction, we discover that the researcher is affiliated with a national tobacco company. Is this affiliation sufficient to warrant labeling the study flawed and biased? Absolutely NOT! Before rejecting findings of any study, we must first determine that the study if flawed to an extent that we have no confidence that the findings are valid.
If we find that the sample used in the study was selected properly, that the procedures were carried
out properly, that appropriate data were collected, and that appropriate statistical techniques were used to analyze the data, then we have very little basis for rejecting the findings. No matter how coincidental or suspicious the researcher's affiliation appears to be, it should not serve as the whole basis for rejecting or accepting a study's findings, regardless of how much they may appeal to or assault our sensibilities. However, researchers' affiliations should serve to alert the evaluator to be watchful for possible indications of bias in the report and throughout the design of the study. Above all, evaluating research demands objectivity on the part of the evaluator. Whether you accept or reject a study's findings, do so on the basis of
objective criteria - the sort of criteria we'll be learning about in this course.
Literature Review
Compared to a master's thesis or doctoral dissertation, the literature review in a journal article is scant. This is usually due to the space constraints imposed by most modern journals. The literature review is incorporated in the Introductory Section, and identifies the most salient research related to the topic currently under study. In evaluating this area, you should check to be sure the researcher has addressed the most relevant research on the subject.
I'm often asked how a student can check this sort of thing if they have no background in a particular area. Nearly every field of inquiry has a handful of researchers and writers who tend to contribute a lot. Every mature field of study also has some amount of seminal research - research that forms the basis for the field of study. As you continue to read more and more research in a particular area, you will become accustomed to seeing the same authors and studies referenced in review after review. When you come across a study that doesn't reference these important authors and studies, you should wonder why they were not included in the literature review, especially if the findings of those studies differ from the direction in which the current study is intending to go.
You should feel comfortable, as an evaluator, that the researcher has done an adequate job of reviewing the available research in the area. If you have no idea about a particular area, you can, of course, assume that the researcher has done a credible review. A better approach though, if you have the time to do so, would be to research the area a bit yourself and check to see if the researcher has, indeed, captured the most relevant research in his or her area.
Constructs or Variables
Every quantitative study should clearly identify and define the variables or constructs being studied and provide some indication of how they will be measured. When variables or constructs are defined in terms of how they are measured, we call them operational definitions. An example of an operational definition would be to define academic achievement in terms of a subject's score on some standardized achievement test. Similarly, one could operationally define a construct, such as intelligence, in this way: "Intelligence is defined by the subject's score on the Wechsler Intelligence Scale." A research report should clearly define all variables used in the study in measurable terms.
Research Hypotheses, Research Questions, and Research Objectives
Just as you need a road map to guide you in unfamiliar territory, research hypotheses, questions, and objectives can guide both the researcher and the evaluator in a research study. For the evaluator, they show where the researcher is intending to go with the study and may even, in the case of a research hypothesis, indicate when the end is reached.
First of all, it's important to remember that one or the other of these is all that is required in a research report. The research hypothesis is an educated guess about the outcome of a study. A research hypothesis is not appropriate for all research designs. For instance, descriptive research studies will usually never have a research hypothesis. Since descriptive studies are typically done in areas where there is little if any prior knowledge or research, it would be quite difficult to have an educated guess as to such a study's outcome. However, there are other areas of inquiry where enough previous work may have been done to give the researcher a good estimate of the possible outcome of a particular study. It's in these studies (usually experimental studies) where research hypotheses are most commonly found.
Two general classes of hypotheses are null and directional hypotheses. The null hypothesis states that "there will be no statistically significant difference between two (or more) groups of subjects on a particular dependent variable as a result of some independent variable." For example, "there will be no statistically significant difference in academic performance on a 9th grade standardized math examination between students who tested in brightly colored rooms and students who tested in pastel or neutral colored rooms."
One reason researchers use the null hypothesis is because they have no reason to assume a direction. In our example, therefore, if the researcher has no reason to believe that students in brightly colored rooms would do significantly better or worse than students in the other colored rooms, then the null hypothesis would be needed.
On the other hand, if the researcher has reason to suspect a definite direction in the outcome of the study based on previous research or theory, then it is appropriate for the researcher to state a directional hypothesis. For instance, our example above might turn out like this if phrased in a directional form: "Subjects who test in a brightly colored environment will score higher than subjects who test in pastel or neutral colored environments on a 9th grade standardized test of mathematics." Notice that this statement not only predicts there will be a difference between the groups, but states the direction of the difference. That is what makes it a directional hypothesis. If the statement had only said that there would be a difference in academic performance between the groups, without saying which one would do better, would not be a directional hypothesis. In fact, it would be an alternate form of the null hypothesis.
Please understand that when a researcher states a null hypothesis, it is not that he or she necessarily wants to find no significant difference. It's just that there is not enough information for the researcher to confidently predict a direction in the outcome, so the null hypothesis is posed. There are occasions when a researcher may be hoping for no significant difference between groups (or relationship between variables) - we'll talk more about those occasions later in the course.
Researchers are under no obligation to state a hypothesis in their research. Nor are they obliged to state questions or objectives. The researcher may use which ever form (or combination of forms) that seem appropriate to his or her research. Having said that, though, it is important that the researcher clearly state at least one of these in their study.
The adjective research in research hypothesis, research objective, and research question signifies that the statement is concise, grounded in theory or previous research, and explicitly defines the important variables in the study and their relationship to each other. Sometimes, a research report does not have a clear, concise statement that describes the variables and their relationships. As the authors of your text state on page 96, "Some researchers only indirectly refer to their hypotheses, questions, or objectives in the introductory section of their reports. ... This is not a weakness in the study itself, but only in its reporting."
If you can't find a good hypothesis, objective, or questions in the introduction, you should read the rest of the report very carefully. First, you're not sure what the researcher is setting out to do in the study. And, second, if the researcher's report writing is poorly done, perhaps there are other, more serious, weaknesses elsewhere in the study. If after reading the entire study, you find it to be well done, then you may fault the researcher for poor report writing skills, but you may also have confidence that the findings are valid.
Research Procedures
Sampling
Why do researchers sample? Quite simply because it is too difficult and expensive to study entire populations. A population is typically defined as a group or collection of subjects that is too large to be conveniently studied en masse. The researcher's only recourse, then, is to sample a manageable group from the population (called a sample), study them, then make appropriate generalizations back to the population.
Another important question is how do researchers make such generalizations? Well, they begin by selecting the sample in such a way that it retains a certain amount of similarity or representativeness with its parent population. The simplest way of doing this is to randomly select the sample. To be random a sampling method has to meet two criteria:
- Each member in the population has an equal opportunity of being selected for the sample (equality)
- Selecting a member has no effect on the selection of any other member (independence)
Random Sampling Methods
- Simple Random Sampling Methods
-
- Simple random sampling is like blindly reaching into a hat full of slips of paper with numbers on them and pulling one slip out after another. The order of the numbers selected (your sample) will be completely random. Notice that every slip of paper will have an equal opportunity of being selected each time and the selection of any particular slip of paper has no impact on the selection of any other slip.
Every time a member is sampled from a population, a small amount of error is generated, called sampling error. Random sampling methods generate the least amount of sampling error of all sampling methods. In fact, there are a class of statistics, called parametric statistics (which you'll learn about in a later lesson), that are able to estimate and cancel out random sampling error.
Because random sampling methods produce the least amount of sampling error, we say that a sample that has been selected randomly from a population has a higher level of population validity than one that was selected nonrandomly. A degree of population validity of a sample also depends on the size of the sample (addressed in more detail below). A sample with a high degree of population validity is said to be representative of the population from which it was drawn, and, thus, can be generalized back to the population more easily and confidently than a sample with low population validity.
-
- Stratified Random Sampling Methods
-
- Another random sampling method is called stratified random sampling It's more complex than simple random sampling, but is sometimes necessary. The limitation of simple random sampling is that it cannot guarantee all attributes of a population are equally represented in the sample. For example, if I select a sample of 100 subjects from a large population containing 60% males and 40% females, there is no certainty that the sample I select will have exactly 60% males and 40% females. But, if it is important to the researcher to have a sample that is representative of the population in terms of the relative percentage of males and females, then he/she must use a stratified sampling method.
Stratified random sampling is done in two stages:
- Divide the population into the strata (attributes) of interest.
- In each strata, draw a simple random sample of the number of subjects needed to meet the percentage.
For example, If we want a sample size of 1000 subjects that retains the relative gender percentage in the population, there would be two strata (males and females). We first randomly select 600 subject from only the males in the population. Then we randomly select 400 subjects only from the females in the population. This way we retain the gender percentage in the sample. As you can imagine, if the number of attributes of interest increase, the number of strata also increase, and the method becomes even more complex. So, for instance, if we want our sample to mirror the population not only in gender distribution but also in racial distribution (say, Asian, black, Hispanic, and white), then we would have to randomly select from 8 different strata in the population (Asian females, Asian males, black females, black males, Hispanic females, Hispanic males, white females, and white males) each with its own unique percentage distribution.
Nonrandom Sampling Methods
But, not all methods of sampling are random. There are several nonrandom methods, all of which generate more sampling error than random methods. Furthermore, there is no statistic that can estimate and cancel nonrandom sampling error. So, the use of nonrandom sampling techniques usually results in less confidence that the sample is truly representative of the population from which it came and, thus, makes generalizing the results more difficult.
Click here to learn about some of the more common nonrandom sampling methods. Some of them are mentioned in your textbook; some are not, but you may see them used in research studies you review in this course.
Sample Size -- How much is enough?
Factors Influencing Sample Size
Because of the error inherent in every sample, there is a risk that the sample is not truly representative of the population from which it was drawn. Researchers identify this risk in terms of the level of confidence they have that the results of their data analysis will be true. As you can imagine, this confidence will always be less than 100%. The amount of risk is related to the size of the researcher's sample. Simply stated, the larger the sample, the greater the confidence that results will be true (and the less the risk that they will be erroneous).
Confidence Level and Precision
To be more accurate, risk is specified by two interrelated factors:
- the confidence level the researcher desires to have in the results, and
- the precision (or reliability) range.
To minimize risk, researchers want a high confidence (usually 95 or 99 percent) that the results obtained from the sample are actual values that would be obtained from any other sample from the same population. They also would like the true value to lie somewhere within a small range around the value measured in the sample. If this is confusing, consider the following analogy by Sawyer (November-December 1971, Statistics Confuse Me, Grandfather, Internal Auditor, Vol. 28, No. 6, pg 49):
A baseball pitcher may feel that he can get very few of his pitches (perhaps 10 percent) over the exact center (small precision range) of home plate. But since home plate is 17 inches wide, he may feel that he can get 95 percent of his pitches over the center of the plate with a precision of plus or minus 8 1/2 inches (a 95 percent confidence level). If the plate is widened to 30 inches, he may feel 99 percent confident.
In other words, the more precision and confidence the researcher wants, the larger the sample has to be to assure it. Typical confidence levels are 95 percent and 99 percent, while a typical precision value is 5 percent. But that still doesn't answer the question of how large does the sample have to be.
Determining the Size of a Random Sample
Once the desired degree of precision and confidence level are determined, there are several formulas that can be used to determine sample size depending on how the researcher plans to report the results. If reporting results as percentages (proportions) of the sample responding, use the following formula:

If reporting results as means (averages) of the sample responding, use the following formula:

If reporting results in a variety of ways, or if you have difficulty estimating percentage or standard deviation of the attribute of interest, the following formula may be more suitable:
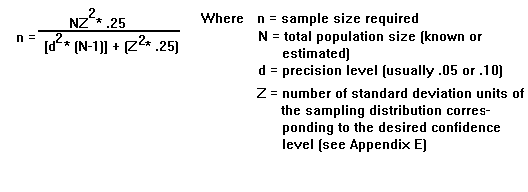
Although it's not immediately clear from these formulas, it doesn't take a relatively large sample size to statistically represent a population. To illustrate this, by computing how large a sample we would need to select from a population size of 10,000 to give us a 95 percent level of confidence that the results of the sample would not occur by chance more that 5 percent of the time. Note that if we used a statistical table of Z values, we would find that a 95 percent confidence level is related to a Z value of 1.96 (this value is necessary for use in the computation). So, we have a population (N) of 10,000, a 95 percent confidence level and a 5 percent precision level (d = .05, Z = 1.96). The sample size becomes:
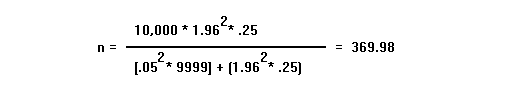
So, a representative sample of 370 (369.98 rounded up) would be sufficient to satisfy your risk level, and would signify that any results from the sample would occur again and again in the general population (using different samples) 95 or more percent of the time. If instead of 10,000, the population size were 1,000,000, redoing the computation would reveal that we would need a sample size of less than 400 to retain the 95 percent confidence level. So, as you can see, samples don't have to be as large as you might think to be statistically representative of a large population. If you want to practice using these formulas to estimate sample sizes, you can use this Sample Size Estimator that doesn't require you to do any math at all. When you exit the estimator, you'll be returned to this page automatically.
Determining the Size of a Stratified (or Proportional) Random Sample
Let's say you want to select a stratified (or proportional) sample from a population. You must randomly sample more than one group, and you must know the proportion (percentage) each group represents in the population. Then you simply multiply the proportion of each stratum by the overall sample size (as computed above) to find out how big each stratum has to be. To illustrate, let's say we want to stratify the sample of 370 we computed above into whites and blacks (races), males and females (genders). Let's also say that we determine from census data that in our population of interest, the percentages (proportions) of each strata are as follows:
- Black female = 45.5%
- Black male = 19.5%
- White female = 24.5%
- White male = 10.5%
Then, the sample size needed to be (randomly) selected from each stratum is:
- Black female = 370 x .455 = 168.35 = 168
- Black male = 370 x .195 = 72.15 = 72
- White female = 370 x .245 = 90.65 = 91
- White male = 370 x .105 = 38.85 = 39
Adjusting Sample Sizes When Using Surveys
When researchers use surveys (questionnaires), they must adjust the size of the sample according to the survey response rate they expect to get. For instance, if a researcher expected to get back only 50 percent of the surveys sent out, then he/she should initially send out twice as many surveys as determined by the formula. In general, to determine the needed sample size for a survey, divide the computed sample size by the expected survey return rate.
Volunteer Samples and Nonrespondent Bias
Nearly all surveys conducted in social science research studies are voluntary in nature. This means that subjects receiving surveys have a choice to respond or not. Because no voluntary survey every yields 100 percent response rate, there will always be a group of subjects for which the researcher has no information. Although we don't know anything about people who tend not to respond to surveys, research has been done that reveals certain characteristics about those who do tend to respond to surveys. Knowing something about these characteristics can help researchers and reviewers of research correctly interpret the results of surveys, and avoid inadvertent biases and pitfalls usually associated with using and interpreting results from volunteer samples. The following list provides 22 conclusions about unique characteristics of the volunteer. The list is subdivided into categories representing the level of confidence to be placed in the findings. Within each category, the conclusions are listed in order starting with those having the strongest evidence supporting them. (from Rosenthall and Rosnow, The Volunteer Subject, 1975; pp 195-196):
Conclusions Warranting Maximum Confidence
- Volunteers tend to be better educated than nonvolunteers, especially when personal contact between investigator and respondent is not required.
- Volunteers tend to have higher social-class status than nonvolunteers, especially when social class is defined by respondents' own status rather than by parental status.
- Volunteers tend to be more intelligent than nonvolunteers when volunteering is for research in general, but not when volunteering is for somewhat less typical types of research such as hypnosis, sensory isolation, sex research, small-group and personality research.
- Volunteers tend to be higher in need for social approval than nonvolunteers.
- Volunteers tend to be more sociable than nonvolunteers.
Conclusions Warranting Considerable Confidence
- Volunteers tend to be more arousal-seeking than nonvolunteers, especially when volunteering is for studies of stress, sensory isolation, and hypnosis.
- Volunteers tend to be more unconventional than nonvolunteers, especially when volunteering is for studies of sex behavior.
- Females are more likely than males to volunteer for research in general, more likely than males to volunteer for physically and emotionally stressful research (e.g., electric shock, high temperature, sensory deprivation, interviews about sex behavior).
- Volunteers tend to be less authoritarian than nonvolunteers.
- Jews are more likely to volunteer than Protestants, and Protestants are more likely to volunteer than Roman Catholics.
- Volunteers tend to be less conforming than nonvolunteers when volunteering is for research in general, but not when subjects are female and the task is relatively "clinical" (e.g., hypnosis, sleep, or counseling research).
Conclusions Warranting Some Confidence
- Volunteers tend to be from smaller towns than nonvolunteers, especially when volunteering is for questionnaire studies.
- Volunteers tend to be more interested in religion than nonvolunteers, especially when volunteering is for questionnaire studies.
- Volunteers tend to be more altruistic than nonvolunteers.
- Volunteers tend to be more self-disclosing than nonvolunteers.
- Volunteers tend to be more maladjusted than nonvolunteers, especially when volunteering is for potentially unusual situations (e.g., drugs, hypnosis, high temperature, or vaguely described experiments) or for medical research employing clinical rather than psychometric definitions of psychopathology.
- Volunteers tend to be younger than nonvolunteers, especially when volunteering is for laboratory research and especially if they are female.
Conclusions Warranting Minimum Confidence
- Volunteers tend to be higher in need for achievement than non-volunteers, especially among American samples.
- Volunteers are more likely to be married than nonvolunteers, especially when volunteering is for studies requiring no personal contact between investigator and respondent.
- Firstborns are more likely than laterborns to volunteer, especially when recruitment is personal and when the research requires group interaction and a low level of stress.
- Volunteers tend to be more anxious than nonvolunteers, especially when volunteering is for standard, nonstressful tasks and especially if they are college students.
- Volunteers tend to be more extroverted than nonvolunteers when interaction with others is required by the nature of the research.
Borg and Gall (Educational Research. Third Edition, New York: Longman, Inc., 1979) have suggested how surveyors might use this listing to combat the effects of bias in survey research. For example, they suggest that:
The degree to which these characteristics of volunteer samples affect research results depends on the specific nature of the investigation. For example, a study of the level of intelligence of successful workers in different occupations would probably yield spuriously high results if volunteer subjects were studied, since volunteers tend to be more intelligent than nonvolunteers. On the other hand, in a study concerned with the cooperative behavior of adults in work-group situations, the tendency for volunteers to be more intelligent may have no effect on the results, but the tendency for volunteers to be more sociable could have a significant effect. It is apparent that the use of volunteers in research greatly complicates the interpretation of research results and their generalizability to the target population, which includes many individuals who would not volunteer. (pp 190-191)
End of Week 1 lesson
| Assignment For Next Week |
| Gall: Chapter 1 (pp.4-16) & 6 |
| SB: Huck Chap 1 |
| Guide: Ch 1, Appendix |
|